Understanding Classification models : A beginners guide
Concepts, Use cases and best practices

Welcome back to StatsTrail! Today, we will take a brief walk-through of classification models and their applications across industries. We will also touch upon some key considerations when building models based on classification techniques.
The classification model is one of the most favored machine learning techniques among data analysts. Tinkering with data attributes, model parameters, or even exploring advanced classification methods to achieve incremental gains is where many of them spend most of their time.
I would like to briefly cover the basics of classification techniques, which may be helpful for new analysts who are just starting their careers and looking to explore this area.
What is Classification technique
A classification technique is used to categorize data into predefined classes. For example, we can categorize our customer base based on whether they are likely to respond to a campaign or not (i.e., Yes/No), using historical campaign response data. Another example is predicting whether a customer will churn or stay in the system (again, a Yes/No category).
In these scenarios, the Yes/No outcome that we aim to predict is called the dependent variable, while the various attributes related to customer transactional behavior or demographics—used to make the prediction—are referred to as independent variables.
We can classify data into two or more categories. If we classify into two categories, it is known as binary classification. If there are three or more categories, it is referred to as multi-class classification.
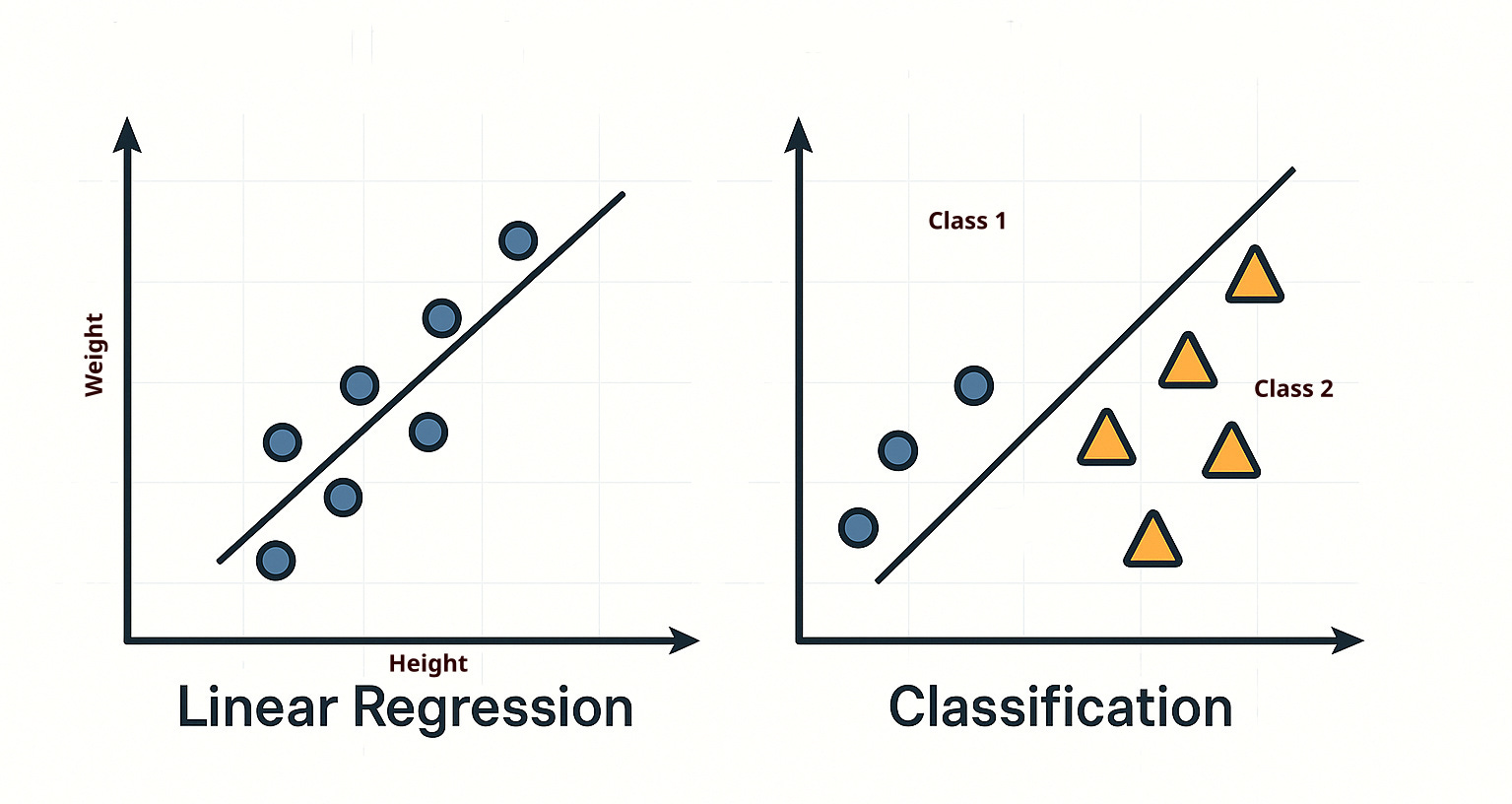
How it is different as compared to linear regression
Let’s say, in the earlier example, instead of classifying whether customers will respond to a campaign, we are asked to predict how much they will spend after receiving the campaign. In this case, we need to predict an actual value—such as the amount a customer might spend—which can range continuously from 0 to some maximum amount. These values could be in the hundreds, thousands, or even more.
In such scenarios, instead of using a classification model, we use a linear regression technique, whose primary objective is to predict continuous variables. Examples of continuous predictions include: how many days a customer will take to respond, how much they will spend, and similar cases.
Classification models are not suitable for predicting continuous outcomes, which is why linear regression is the appropriate choice in these situations.
What are different types of classification models
Logistic Regression
One of the most basic yet highly popular techniques across industries.
Based on odds of certain events.
Decision tree
Extremely easy to understand and interpret
It creates a tree-like structure to classify data based on input features
While useful for exploratory analysis, it is not always recommended for prediction tasks as it tends to overfit the data.
Random forest
One of the most favored techniques in the data science community
It builds multiple decision trees and aggregates their results to make final classifications
Random forests handle over-fitting much better than individual decision trees
Apart from these three popular techniques, Support Vector Machines (SVM), Naive Bayes, and K-Nearest Neighbors (KNN) are also commonly used, depending on the nature of the business problem.
Use cases of Classification models
Almost all industries—including retail, banking, finance, insurance, and telecom—have successfully implemented classification models. Let’s take a look at some well-known use cases:
Retail
Campaign response modeling – Predict customers who are most likely to respond to campaigns, allowing for more targeted marketing efforts.
Acquisition models for new products – Identify customers who are most likely to try newly launched products.
Telecom
Churn modeling – One of the most critical analyses in the telecom industry; it helps identify customers who are likely to churn.
Prepaid to postpaid acquisition – Customers moving from prepaid to postpaid plans are often more valuable and generate higher revenue.
Banking and finance
Fraud detection – Analyze transactional patterns and identify outliers that are more likely to be fraudulent using classification techniques
Loan default prediction – Identify customers who are at risk of defaulting on loans such as home loans or personal loans
Manufacturing
Fault detection – In the manufacturing industry, it is essential to predict which equipment is likely to fail in the near future and proactively address the issue.
We can clearly see how powerful and versatile classification techniques are. In fact, many recent AI algorithms have been built upon classification models as a foundation to further enhance their performance.
Few important things to be aware of while building classification models
Business Understanding
One of the most crucial and often overlooked steps—even before preparing datasets—is gaining a thorough understanding of the business problem. As we know, the success of a classification model heavily depends on selecting the right set of independent variables, which is not possible without proper business understanding.
It is essential to gather information from stakeholders and subject matter experts related to the given business problem. Often, these individuals provide valuable insights or clues that may not be evident through data alone.
Exploratory analysis
In the fast-paced world of machine learning and AI, people sometimes skip initial data exploration and move straight to modeling by adding as many variables as possible. However, steps such as analyzing descriptive statistics (e.g., mean, median), and conducting univariate analysis, play a pivotal role throughout the model-building process.
These steps reveal important trends, seasonality, and hidden patterns in the data that help in optimizing feature selection and improving model performance.
Model evaluation
After building the initial model, it's essential to evaluate it using the right metrics and across different datasets to ensure it doesn’t under-fit or over-fit over time.
Most ML algorithms evaluate models using static train/test splits. It is good practice to perform out-of-time validation, especially in industries with strong seasonality, to ensure the model remains robust across time periods.
Key concepts
Throughout the process of building classification models, you will encounter various statistical parameters and concepts that play a crucial role in the model’s success.
Let’s go through a few of the key concepts.
Bias Variance Tradeoff
A simple algorithm may not perform well on training data (high bias) but can yield more consistent results on test data (low variance).
On the other hand, a complex, tree-based algorithm may fit the training data very well (low bias) but might not generalize to new data (high variance).
Hence, it is crucial to strike a balance between bias and variance to achieve reliable results.
Logistic regression is generally considered an example of high bias and low variance whereas Decision trees are often characterized by low bias and high variance
Precision-Recall tradeoff
Let’s say 10 out of 100 customers actually responded to a campaign, and your model predicted that 20 customers would respond. Out of those 20, only 5 were correctly predicted.
In this scenario:
Precision = 5/20 = (Correctly predicted responders) / (Total predicted responders)
Recall = 5/10 = (Correctly predicted responders) / (Total actual responders)
Understanding whether to prioritize precision or recall depends on business objectives and constraints such as campaign cost or resource availability
For high-cost campaigns with tight marketing budgets, it is crucial to optimize precision to target only the most likely responders.
For low-budget campaigns like email outreach, enhancing recall might be more beneficial, even at the cost of lower precision.
Closing note
Machine learning models based on classification techniques are among the most powerful and widely used tools for solving a variety of business problems. Starting with something as simple as logistic regression, results can be significantly enhanced by leveraging more complex, tree-based models.